Echoes Over Time
Unlocking Length Generalization in Video-to-Audio Generation Models
Long-Video to Audio Examples:
Our MMHNet framework:
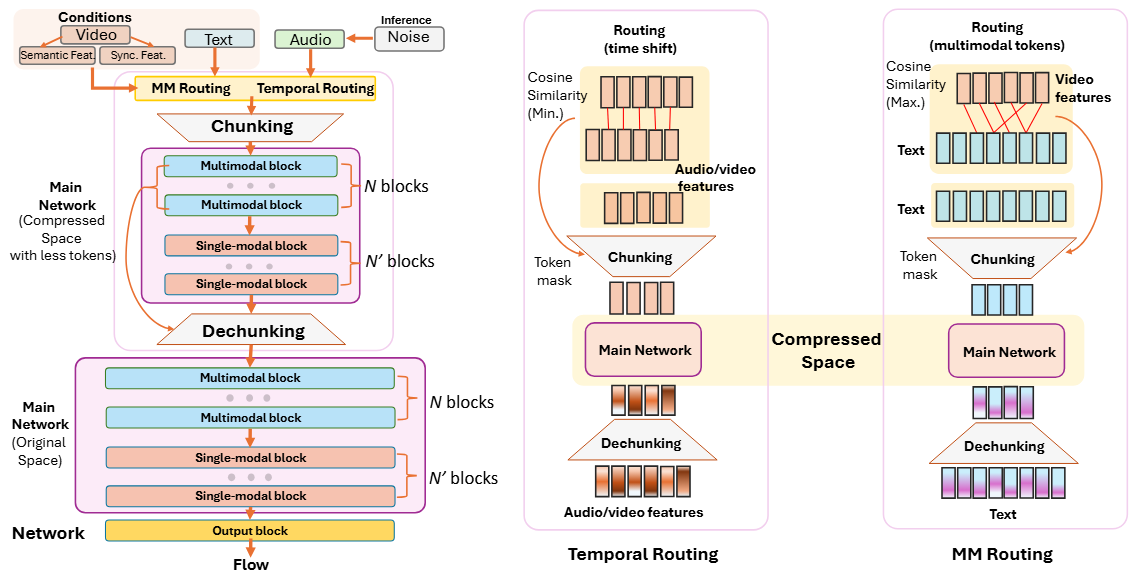
Abstract. Scaling multimodal alignment between video and audio is challenging, particularly due to limited data and the mismatch between text descriptions and frame-level video information. In this work, we tackle the scaling challenge in multimodal-to-audio generation, examining whether models trained on short instances can generalize to longer ones during testing. To tackle this challenge, we present multimodal hierarchical networks so-called MMHNet, an enhanced extension of state-of-the-art video-to-audio models. Our approach integrates a hierarchical method and non-causal Mamba to support long-form audio generation. Our proposed method significantly improves long audio generation up to more than 5 minutes. We also prove that training short and testing long is possible in the video-to-audio generation tasks without training on the longer durations. We show in our experiments that our proposed method could achieve remarkable results on long-video to audio benchmarks, beating prior works in video-to-audio tasks. Moreover, we showcase our model capability in generating more than 5 minutes, while prior video-to-audio methods fall short in generating with long durations.